К вопросу о переводе на русский бинарных файлов
Автор pashak
Большинство из вас не учитывает вариант, когда исходные коды программы недоступны (например, программа вообще другого автора), поэтому я утверждаю, что менять строки в исходниках — это один из самых лёгких, но не всегда доступных вариантов.
Автор темы поставил хороший вопрос: как поменять данные внутри уже скомпилированной программы?
Сейчас я попытаюсь ответить на этот вопрос.
Итак, с помощью компилятора программист переводит свой код на языке программирования в машинный (бинарный, двоичный) код. Последний представляет собой набор двоичных инструкций, указывающих процессору, какую операцию выполнять, например, суммировать данные из регистров процессора.
Грубо говоря, бинарный код линеен, т.е. выполняется последовательно, операция за операцией, что значит, что его можно было бы даже записать на магнитную ленту и вот так выполнять. Т.е. процессор знает, какой байт программы нужно выполнить следующим. Однако в нём присутствуют операторы управления выполнением кода (соответствующие, например, ассемблерным командам jmp, jnz и др.), которые могут повлиять на значение адреса следующей команды. Т.е. если бы мы работали всё с той же кассетной лентой, то нам в таком случае пришлось бы её перематывать (вперёд или назад, в зависимости от того, меньше или больше адрес следующей команды). Таким образом достигается ветвление, хотя физически данные записаны последовательно.
К чему я это?
К тому, что по общепринятому соглашению выполняемый код и данные (строки или числа), с которым он работает, располагаются в разных сегментах, т.е. отделены. И к тому, что код оперирует не с данными, а с адресами этих данных. Из этого следует, что различные данные не должны пересекаться (накладываться друг на друга). И кстати, да, адресом данных является адрес первого байта этих данных. И на такие данные налагается требование неизменения размера.
Давайте лучше пример, а то для вас то, что я пишу, наверняка непонятно с первого раза. Рассмотрим всё схематично, потому что я не углублялся в познание машинного кода и не могу сказать достоверно коды операций.
Итак, у нас есть код:
printf("Hello, world!");
printf("Another string.");
Он будет переведён в машинный код примерно следующего вида (в фигурных скобках указаны комментарии):
{несколько директив для указания, как работать процессору}
{начало сегмента кода}
{код, вызывающий функцию printf с параметром Х}
{код, вызывающий функцию printf с параметром Y}
{тут идёт много неинтересного нам кода}
{заканчивается сегмент кода, начинается сегмент данных}
{адрес X, с которогоначинается перваая строка}Hello, world!{нулевой байт, означающий конец строки}
{адрес Y, с которогоначинается перваая строка}Another string.{нулевой байт, означающий конец строки}
{здесь и дальше идут неинтересные нам данные}
Адреса для данных (в данном случае, для Hello, world! и Another string.) резервируются в процессе компиляции и предполагается, что они не могут быть изменены, т.к. они используются в коде. Как видим, первая строка отделена от второй строки нулевым байтом, и если мы заменим его на пробел, то при обращении к первой строке будут выведены обе строки (!!!). Здесь и просматривается правило ненарушения размера.
Однако это правило можно обойти, если в коде, ссылающемся на строку, изменить адрес этой строки. Например, если в русской версии эта строка больше на 2 символа, то при локализации нужно записать эту строку на 2 символа раньше (но так, чтобы она не пересекалась со строкой перед ней) и в коде, ссылающемся на эту строку, уменьшить адрес на двойку.
Другой темой является поиск адреса, ссылающегося на эту строку. Но это не так сложно. Зная адрес первого символа строки можно запросто найти участок кода ссылающегося на этот адрес. Для этого нужно воспользоваться следующим правилом:
Адрес строки нужно дополнить четверкой, которую нужно поставить на чётную позицию (позиция отсчитывается слева, с единицы): 5DAB8 — 45DAB8.
Разбейте адрес строки (45DAB8) в шестнадцатиричном виде по 2 числа (45 DA B8) и запишите полученный список в обратном порядке (B8 DA 45) и дополните нулями до восьми знаков (B8DA4500).
Теперь попробуйте поискать получившееся число (B8DA4500) по всей программе. Найденное вхождение, а их может быть несколько, и будет ссылкой из кода на нужную нам строку. В случае чего, эту ссылку можно подкорректировать.
Еще ближе к практике
Когда-то мне довелось перевести Valve Hammer Editor (VHE) на русский. А "зашитых" строк там было полно. Вот так я и научился совершать перевод.
Итак, для примера нам понадобится WinHex и VHE 3.5. Сначала нужно выполнить перевод PE-части. Есть немало сторонних программ, с помощью которых можно с лёгкостью это сделать. После этого вы сможете увидеть, какая часть интерфейса осталась нерусифицированной, скорее всего, она и будет внутри кода.
Находим какую-нибудь строчку на английском, которая на русском будет длиннее.
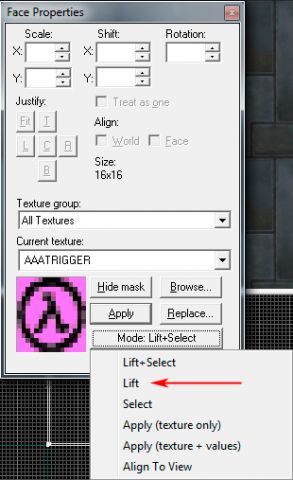
Например, Lift — в данном контексте Подъём, Установка, Переключение на текстуру.
Открываем в WinHex исполняемый код VHE. Ищем "Lift", но таких адресов есть несколько. Выбираем именно тот, где фраза окружена нулевыми байтами — адрес D3978.
![]()
Теперь ищем ссылки на эту строчку: Ctrl+Alt+F, ищем число 78394D (переделанный по правилу адрес). Оно нашлось по адресу 1А112. Это значит, что код из этого места ссылается на данные по адресу D3978. Меняем 78 на 77.
![]()
Такая замена означает, что строчка должна начаться на один символ раньше. Теперь "Lift" меняем на "Подъём", но запись начинаем с одного символа раньше.
![]()
Теперь можно глянуть на результат.
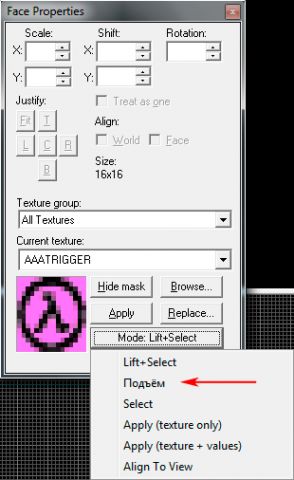
Так поступаем в любом случае, если невозможно записать русскую строчку так, чтобы она не накладывалась на следующую.
Для двухбайтных кодировок картина аналогична. Для примера помучаем всё тот же VHE (правда, я не знаю, как обстоят дела с не-Windows программами, но думаю, что аналогично). В WinHex есть замечательная штука — поиск Unicode. Попробуем перевести ресурс с Unicode — заголовок меню File (это, конечно, можно сделать в PE Explorer или другом PE-редакторе, но для примера, я думаю, сойдёт).
Ctrl+F, ставим галочку "Учитывать регистр" и тип Unicode. Ищем фразу "File". В оригинальном файле она находится на смещении 120E30.
![]()
Для перевода нам понадобится таблица символов UTF-16 (http://www.utf8-chartable.de/unicode-utf8-table.pl).
Находим коды символов 'Ф', 'а', 'й', 'л' в первой колонке (предварительно переключившись на кириллические символы): 0424, 0430, 0439, 043B.
Теперь опять будем пользоваться правилом разбития на 2 знака и записи в обратном порядке.
Записываем с адреса 120E30 следующие данные:
24 04 30 04 39 04 3B 04
![]()
И сохраняем файл. Теперь смотрим на результат.
Готово.
Что касается 4-байтных кодировок, то я не встречал их, но подозреваю, что значения в таких кодировках тоже будут записаны в обратном порядке.